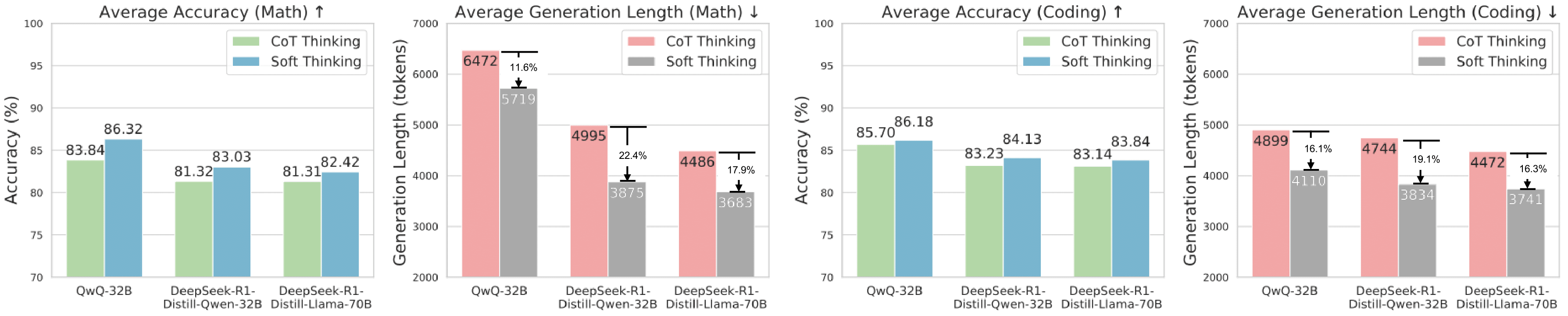
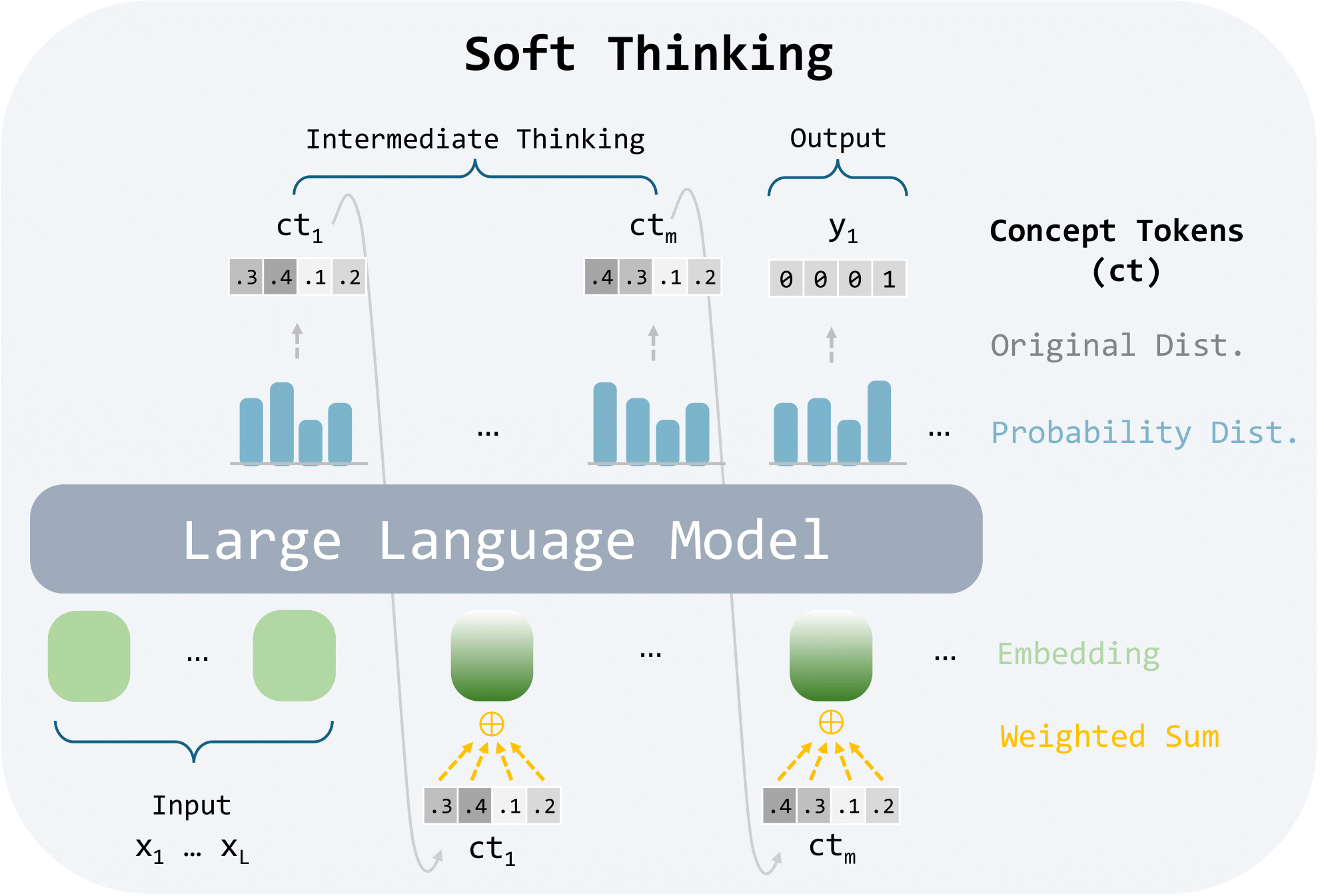

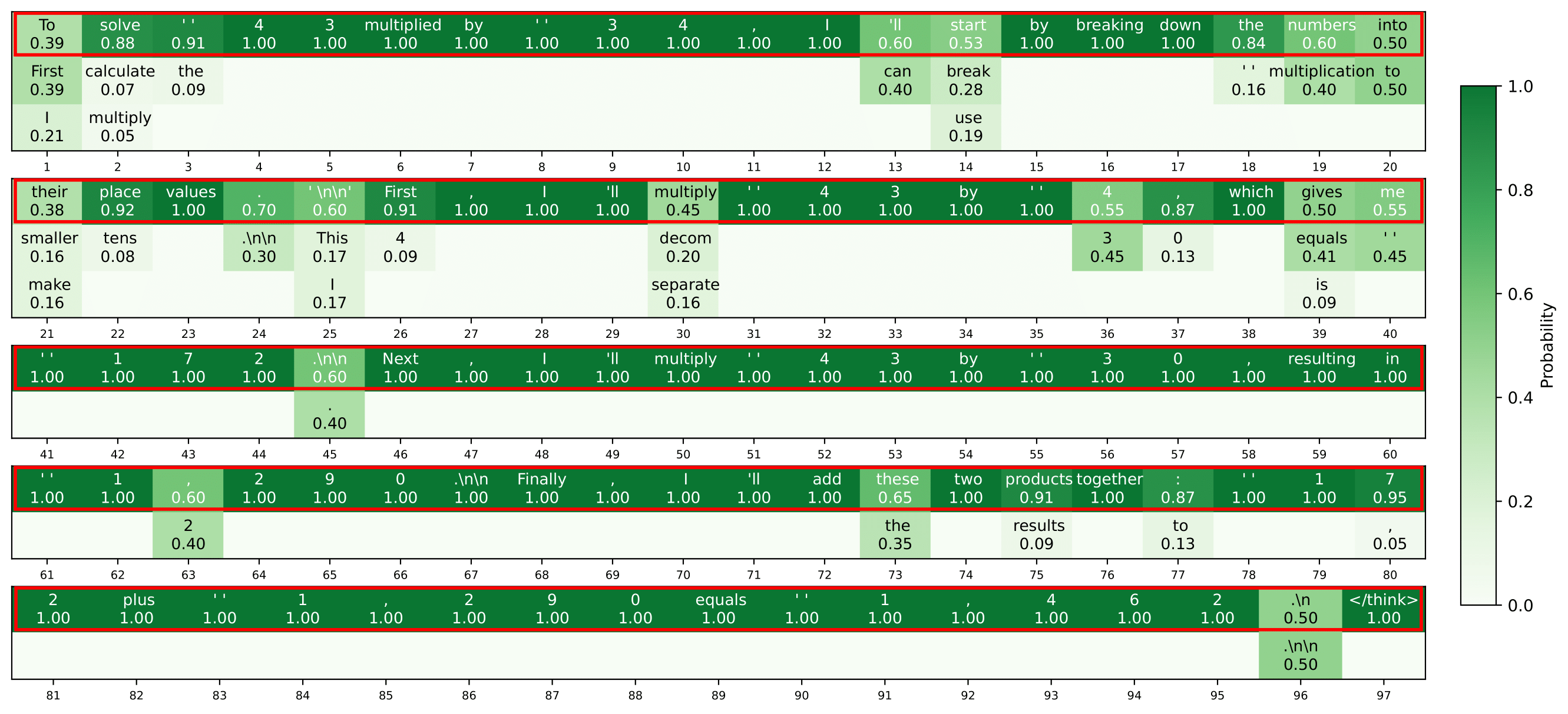
| Method | Accuracy ↑ | Generation Length ↓ | ||||||
|---|---|---|---|---|---|---|---|---|
| HumanEval | MBPP | LiveCodeBench | Avg. | HumanEval | MBPP | LiveCodeBench | Avg. | |
| QwQ-32B [1] | ||||||||
| CoT Thinking | 97.63 | 97.49 | 62.00 | 85.70 | 2557 | 2154 | 9986 | 4899 |
| CoT Thinking (Greedy) | 95.73 | 96.50 | 57.35 | 83.19 | 2396 | 2069 | 7034 | 3833 |
| Soft Thinking | 98.17 | 97.66 | 62.72 | 86.18 | 2638 | 2157 | 7535 | 4110 |
| DeepSeek-R1-Distill-Qwen-32B [2] | ||||||||
| CoT Thinking | 97.25 | 95.13 | 57.33 | 83.23 | 3095 | 2761 | 8376 | 4744 |
| CoT Thinking (Greedy) | 87.19 | 87.54 | 43.36 | 72.70 | 2294 | 1703 | 4702 | 2900 |
| Soft Thinking | 97.56 | 95.33 | 59.50 | 84.13 | 2713 | 2534 | 6255 | 3834 |
| DeepSeek-R1-Distill-Llama-70B [3] | ||||||||
| CoT Thinking | 97.71 | 94.77 | 56.94 | 83.14 | 2711 | 2386 | 8319 | 4472 |
| CoT Thinking (Greedy) | 92.07 | 91.82 | 48.02 | 77.30 | 2192 | 1979 | 5438 | 3203 |
| Soft Thinking | 98.17 | 94.94 | 58.42 | 83.84 | 2498 | 2214 | 6512 | 3741 |
Table 2: Comparison of Soft Thinking and various baseline methods on accuracy and generation length of correct answers across three coding datasets. Best results are highlighted in bold.